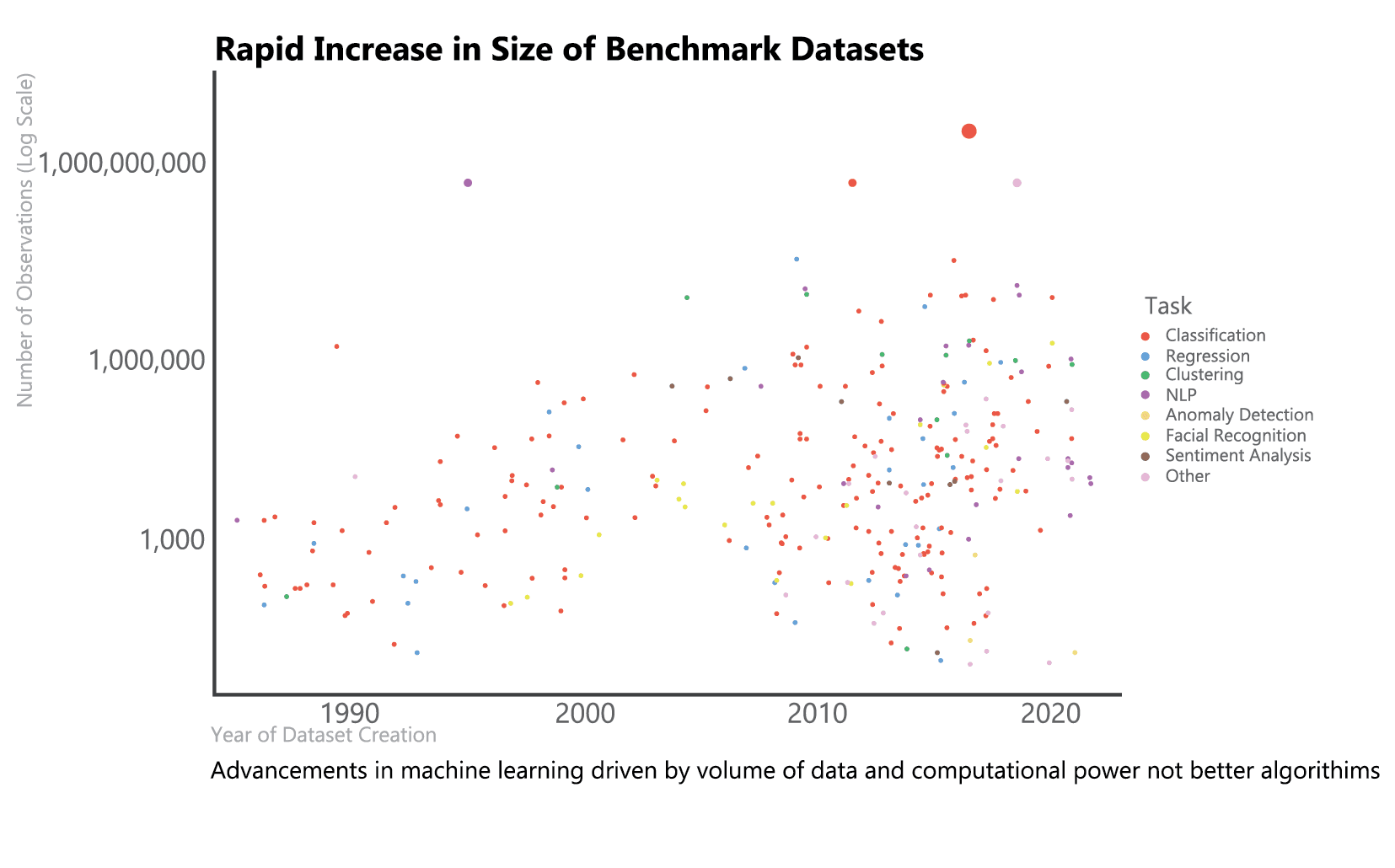
In 2009, Google’s Director of Search Peter Norvig2 explained how Google’s search engine was so effective: “We don’t have better algorithms. We just have more data."3 This quote describes why Google has been so successful, but it also highlights an often-forgotten truth about the history of deep learning: advancements have come from the data, not the algorithms.
Deep learning started gaining traction in 2006, and dramatic improvements in accuracy have enabled the accomplishment of increasingly complex tasks. But deep learning spans back to the ’40s (when it was known as cybernetics), and modern algorithms aren’t very different than what existed in the ’80s (then known as connectionism). The most important factor driving modern success in deep learning is the massive amount of data that is tracked and available due to digitization.4
Massive data isn’t always available, or inexpensive enough for commercial applications. This makes deep learning infeasible for many use cases, because in general, 5,000 labels are needed per category for a neural network to achieve a minimally acceptable baseline performance, and 10,000,000 for it to exceed human performance.6